A field report from the TCXC Labs engineering team.
TL;DR
We built a Claude agent on Anthropic's Managed Agents platform to normalize carrier rate sheets. It worked perfectly on a 100-row smoke test and died at row 65,000 of a real file with prompt is too long: 1017705 tokens > 1000000 maximum. The platform places the agent loop in Anthropic's cloud, but the bridge between the loop and its container is the conversation — every tool result accumulates against a 1M token ceiling that the SDK cannot raise or evict. We rebuilt the same agent on the Messages API with context_management enabled and tools running on our own server. Same model, same autonomy. Source data stays on disk, only summaries cross the wire, and the run holds steady at 30–50K tokens regardless of file size. A 125,473-row Tata Communications rate sheet now finalizes in eight turns for about $2.
The job
Carriers send us rate sheets every day. The shapes are wildly inconsistent: zipped CSV bundles split by quality tier, single 4 MB XLSX workbooks with 125,000+ rate rows buried under merged header cells, and everything between. The job is mechanical but unforgiving — a single misplaced decimal in a rate row routes minutes at the wrong price and burns money fast.
This is the textbook shape for an LLM agent: variable input, semantic mapping, self-verification. So we built one on Managed Agents.
What worked
Managed Agents gives you a hosted agent harness: sessions, a cloud container with bash and Python pre-installed, server-side event streaming, conversation history, and a clean SDK. On a smoke test with three small CSVs (31 to 39 rows each), it was excellent. The agent unzipped the archive, identified per-trunk files from filenames, mapped columns, self-verified, and submitted results through a custom tool. End-to-end in under 90 seconds.
If your data fits comfortably inside a conversation, Managed Agents is a genuinely useful primitive. We were ready to ship.
What broke
Then we pointed the same agent at a real file: a 4.2 MB XLSX from Tata Communications with 125,609 rows across three trunks, distinguished by a service-level column.
Our setup pre-extracted the workbook on our server into clean per-sheet CSVs and exposed a single tool to the agent:
get_source_rows({ file_index, start, limit })The agent identified the three trunks correctly from samples, wrote a Python parser inside its container, processed thirteen 5,000-row chunks covering roughly 65,000 rows, and then the session died:
prompt is too long: 1017705 tokens > 1000000 maximum
The arithmetic of a 1M-token ceiling
Claude's context window is 1M tokens. Every get_source_rows response became an agent.tool_result event glued to the conversation:
- 5,000 rows × ~80 chars/row × ~0.25 tokens/char ≈ 60K tokens per chunk
- A 200K-row file at 5K-row chunks = 40 chunks × 60K = 2.4M tokens of raw row data
Chunk size does not matter. Smaller chunks just mean more of them. The total volume crossing the conversation is bounded below by the size of the data the agent has to see, which is the entire file.
What we tried before giving up on the managed runtime
Files API with container_upload. The docs describe a content block that drops uploaded files directly into the container's input directory. The runtime disagrees:
events[0].content[1].type: "container_upload" is not a valid value
Document block with file_id. Accepted for PDF and plaintext, rejected for everything else:
Unsupported document file format: application/zip. Only PDF and plaintext documents are supported.
Explicit context_management. The Messages API supports edit strategies like clear_tool_uses_20250919, exactly the primitive needed here. Managed Agents rejects it at agent creation:
context_management: Extra inputs are not permitted
Auto-compaction events (agent.thread_context_compacted) exist in the event stream but did not fire before we hit the ceiling. By the time they would have, the session was dead.
Per-trunk sessions, column pruning, public tunnels to our backend. All workable in narrow cases, none of them general. A full A-to-Z trunk can be 200K+ rows on its own — even a single trunk exceeds the window. Tunneling chunks into the container bypasses the wire but the bytes still hit the conversation the moment the agent reads them.
The underlying constraint is architectural: Managed Agents puts the loop in Anthropic's cloud and the container next to it, but the only bridge between them is the conversation. Anything that crosses that bridge is tokenized. For tabular data measured in megabytes, the bridge is the bottleneck.
The rebuild
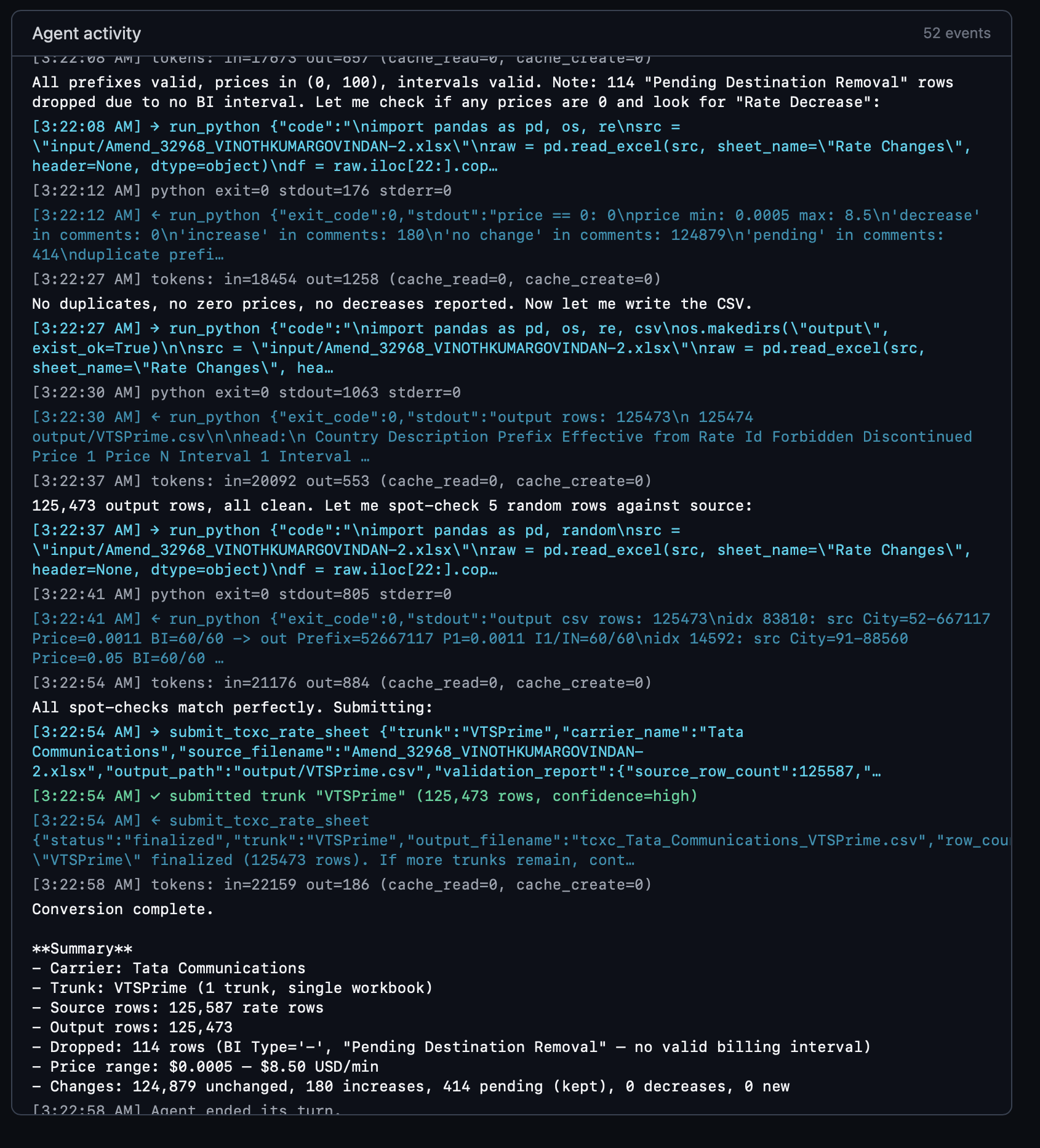
We moved the loop onto our own server, against the plain Messages API. Same model, same self-verification protocol, same output schema. Four things changed:
- Source files never enter the conversation. They sit on local disk, addressable by path.
- Tools execute on our server, not in Anthropic's cloud. A single
run_python({ code })tool spawns Python locally with the source file in scope; only stdout (capped at 32 KB) returns to the agent. context_managementis enabled onmessages.create. Old tool results auto-evict at 200K input tokens.- The agent reads samples and summaries, never bulk rows. File metadata, a 50-row preview, and Python output like
"wrote 124,887 rows, prefix range 1–999999, price range $0.0011–$0.50". Submission references a file path, not a payload; the runner re-reads the CSV from disk and validates every row deterministically before finalizing.
Total token usage holds at 30–50K per job regardless of source size. The same agent handles 200K, 500K, or 2M rows without any code change.
Not coincidentally, this is the architecture Claude Code itself uses: Messages API plus a tool-use loop against a local filesystem. The agent is still fully autonomous — it picks tools, writes its own parsing code, iterates its own verification. The only thing that changed is who owns the container.
What it costs
Because raw rows never enter the conversation, the bill scales with agent turns, not file size:
A 50K-row sheet and a 500K-row sheet take roughly the same number of turns to validate and submit. For a CSP processing dozens of rate sheets a month, the recurring spend is measured in tens of dollars.
Where each runtime belongs
Managed Agents is the right primitive when the data is the conversation: web research, API orchestration, document review under a few hundred KB, anything where you would otherwise build a sandbox from scratch. The hosted observability, session resume, and pre-installed container packages are real advantages.
It is the wrong primitive when the input or output dominates the token budget, when you need explicit context management, or when you would naturally reach for pandas. For those, you want the Messages API and your own loop. You write more code; in exchange you control what enters the model's context, which is what makes the workload feasible at all.
What Anthropic could change
None of the following require model work. All of them are SDK and runtime surface. Any two or three would have kept our Tata run inside the managed harness:
- Expose
context_managementat agent creation. The strategy already exists on the Messages API. Surfacing it on Managed Agents would let the runtime evict old tool results before the ceiling, instead of dying at it. - Ship
container_uploadas a real content block. The docs describe it; the runtime rejects it. Either land it or remove the docs. A working block would route files into the container without crossing the conversation. - Accept XLSX, CSV, and ZIP via the
documentblock. PDF and plaintext do not cover bulk data work. Forcing pre-conversion outside the platform defeats the point of a managed harness. - Add a file-system primitive that bypasses the conversation entirely. "Mount this object store path into the container's input directory" would unlock gigabyte-scale tabular processing without tokenizing a byte of it.
- Fire
agent.thread_context_compactedproactively. A predictable threshold — compact at, say, 70 percent of the window — would make long-running jobs reliable. - Token back-pressure for tools. A way for a custom tool to query remaining context and back off, or to receive a soft warning before a hard failure, would let agents adapt their chunking dynamically instead of crashing at 1,017,705 tokens.
We remain fans of what Anthropic is building. We will revisit Managed Agents the day context_management ships for it or container_upload becomes a real block type. Until then, for large rate sheets, the agent runs on our servers.
Four lessons we are taking forward
- Test against real data on day one. A 90-second smoke test can give you completely misleading confidence. The large files are what reveal the actual constraints.
- The 1M context is a feature, not a budget to fill. Anything you push through a conversation accumulates. Design around what stays out of context, not what fits inside it.
- "Managed" is a tradeoff, not a free lunch. A hosted loop simplifies the harness and constrains the boundary between agent and data. If your bottleneck sits at that boundary, you need to own the loop.
- The agent abstraction is portable. You can run a Claude agent on the Messages API with the same autonomy, tool use, and reasoning quality you get from the managed product. The real question is who provides the container — and for data-heavy work, the answer is you.
If you are building agents against large, messy tabular data, we would love to compare notes. info@tcxclabs.ca.